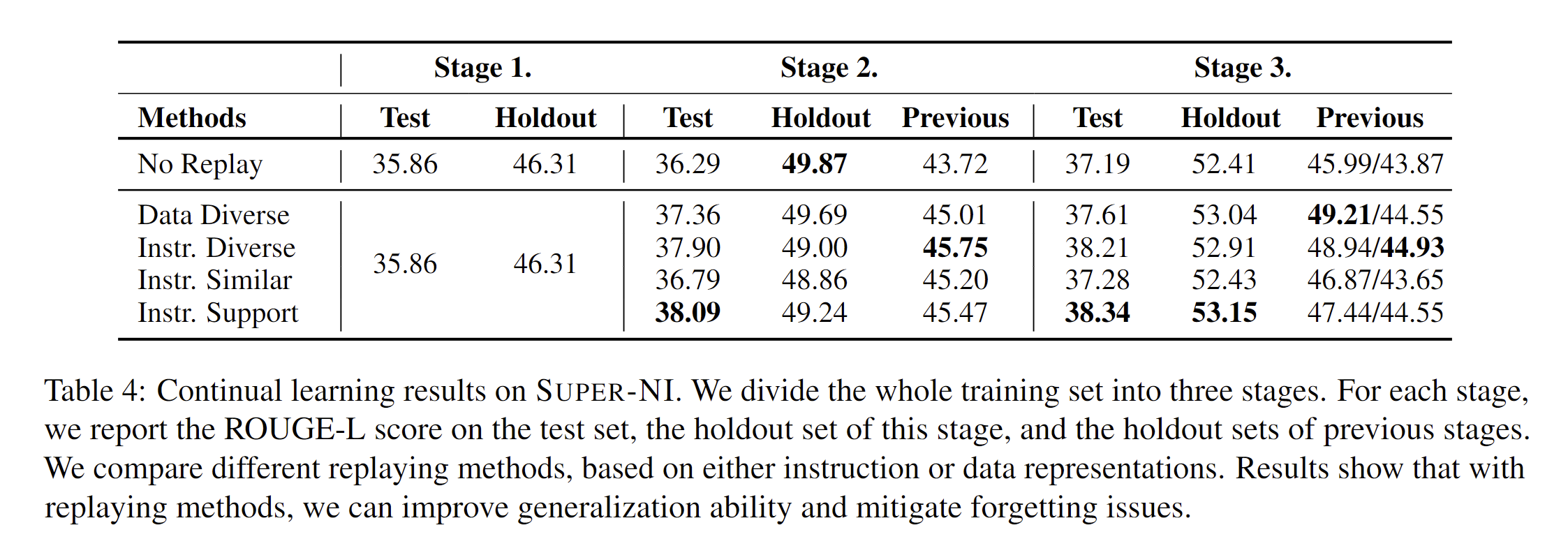
Dynosaur Collection Method
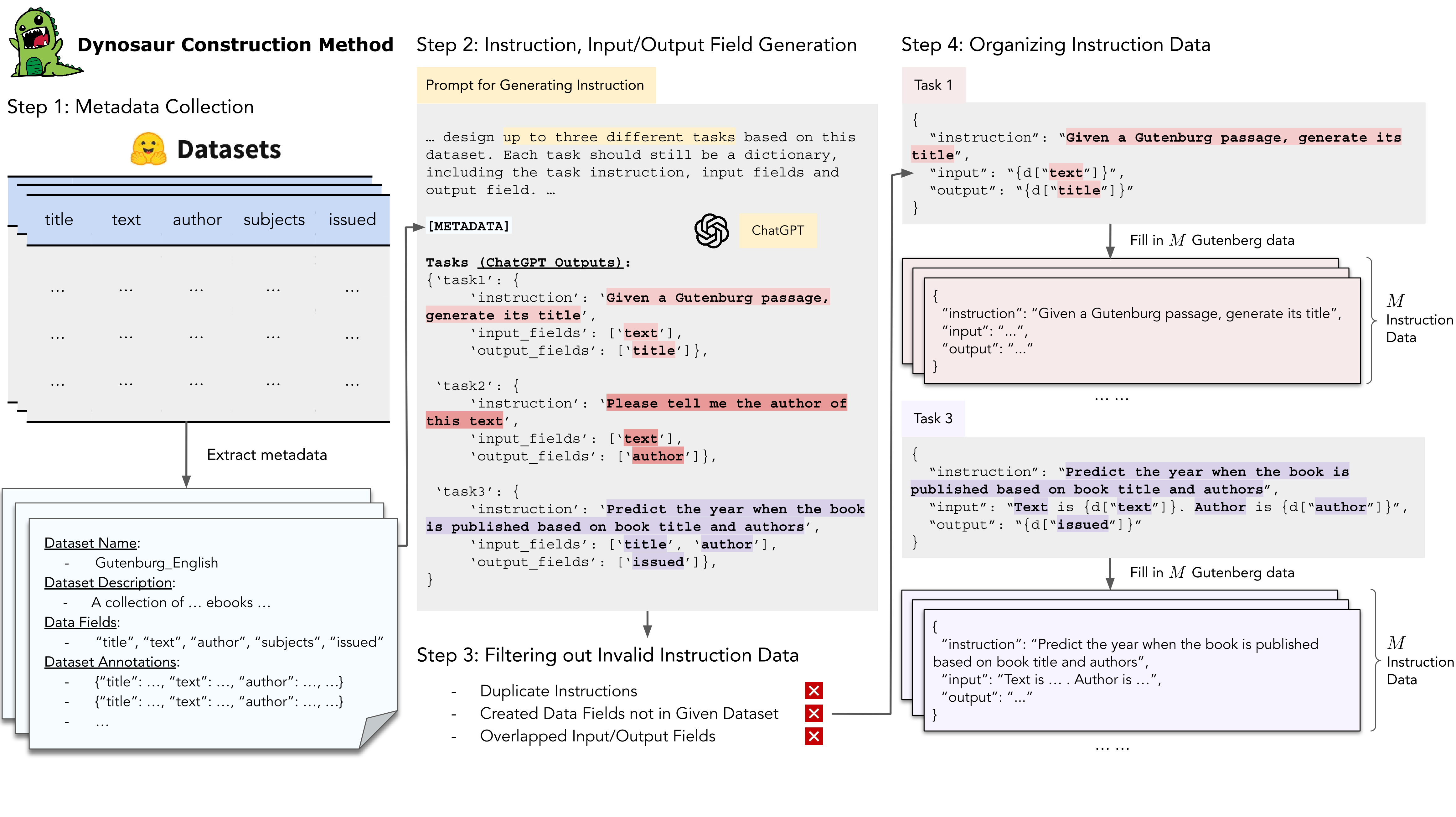
The collection process of Dynosaur consists of following steps:
- Metadata collection:
- Collect dataset name, description, data fields and dataset annotations from Huggingface - Instruction and input/output field generation:
- Prompting LLMs with metadata and outputing multiple instructions and input/output fields - Filtering out invalid instruction data:
- Filtering out duplicate instructions and the ones with invalid input/output fields